Il robot ad autoapprendimento muove autonomamente le molecole, preparando il terreno per la stampa 3D molecolare
Se conosci anche solo un po ‘di scienza, probabilmente sai già che le molecole sono spesso definite “i mattoni della vita”. Costituite da un gruppo di atomi che si sono legati insieme, le molecole costituiscono tutti i tipi di materiali, ma si comportano in modo totalmente diverso rispetto agli oggetti macroscopici rispetto agli atomi. Immagina come un modello LEGO sia fatto di tanti mattoncini piccolissimi: è facile per noi spostare questi mattoni, ma se pensi alle molecole come a questi mattoni, è molto più difficile farlo, poiché ognuno richiede fondamentalmente il proprio set separato di istruzioni.
Un team di ricercatori provenienti da Germania e Corea sta lavorando per capovolgere questa situazione e ha creato un sistema di intelligenza artificiale (AI) che può imparare come afferrare e spostare selettivamente molecole separate attraverso l’uso autonomo di un microscopio a scansione a tunnel (STM) che viene utilizzato per l’imaging di superfici a livello atomico. Quindi, se torniamo alla metafora LEGO, il team ha realizzato un robot autonomo in grado di giocare con i mattoncini LEGO su nanoscala, che potrebbe avere importanti ramificazioni per la stampa 3D molecolare .
Il dottor Christian Wagner, capo del gruppo di lavoro dell’ERC sulla manipolazione molecolare al Forschungszentrum Jülich, ha spiegato: “Se questo concetto potesse essere trasferito su scala nanometrica per consentire che le singole molecole siano specificamente messe insieme o separate di nuovo proprio come i mattoncini LEGO, le possibilità sarebbero essere quasi infinito, dato che ci sono circa 1060 tipi di molecole concepibili “.
I ricercatori del Forschungszentrum Jülich , della Jülich Aachen Research Alliance ( JARA ), della RWTH Aachen University , della Technische Universität di Berlino , del Max Planck Institute for Informatics e della Korea University compongono il team. Recentemente hanno pubblicato un articolo, ” Nanofabbricazione robotica autonoma con apprendimento per rinforzo “, che descrive il loro metodo in Science Advances .
L’abstract afferma: “La capacità di gestire singole molecole con la stessa efficacia dei blocchi macroscopici consentirebbe la costruzione di complesse strutture supramolecolari inaccessibili all’autoassemblaggio. Le sfide fondamentali che ostacolano questo obiettivo sono la variabilità incontrollata e la scarsa osservabilità delle conformazioni su scala atomica. Qui, presentiamo una strategia per aggirare entrambi gli ostacoli e dimostrare nanofabbricazione robotica autonoma manipolando singole molecole. Il nostro approccio utilizza l’apprendimento per rinforzo (RL), che trova strategie di soluzione anche di fronte a grandi incertezze e scarsi feedback “.
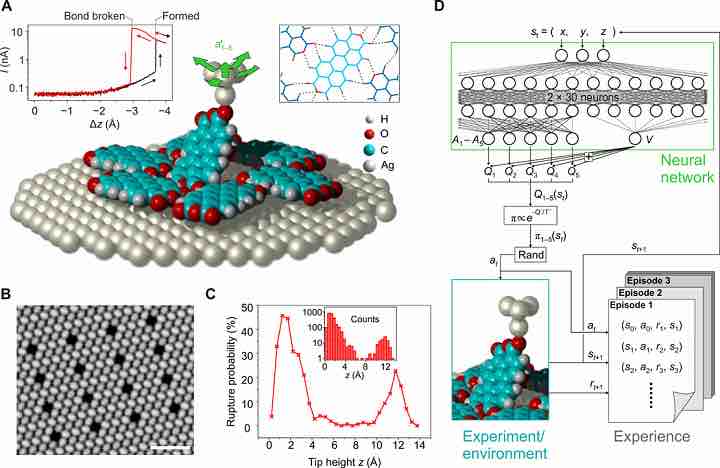
Figura 1. Produzione sottrattiva con un agente RL. (A) Le molecole PTCDA possono legarsi spontaneamente alla punta SPM ed essere rimosse da un monostrato dopo la retrazione della punta su una traiettoria adatta. La formazione e la rottura del legame provocano forti aumenti o diminuzioni della corrente di tunneling (inserto a L). La rimozione è impegnativa, perché PTCDA è trattenuto nello strato da una rete di legami idrogeno (linee tratteggiate, riquadro destro R). L’agente RL può scegliere ripetutamente tra le cinque azioni indicate a′1−5 (frecce verdi) per trovare una traiettoria adatta (insieme di azioni A: ∆z = incrementi di 0,1 Å più incrementi di ± 0,3-Å nella direzione x o y, oppure nessun movimento laterale). (B) Immagine STM di uno strato PTCDA con 16 posti vacanti creati dall’agente RL. (C) Probabilità di rottura del legame ad intervalli di 0,5 Å attorno all’altezza della punta z in funzione di z, basato su tutti gli eventi di rottura del legame accumulati durante gli esperimenti con l’agente RL (riquadro). (D) La funzione Q è approssimata da una rete neurale con 30 neuroni nel primo e 2 × 15 neuroni nel secondo strato nascosto. Questa architettura di rete duellante (39) presenta uscite separate Ai e V, con Qi = V + Ai per le azioni a′i = 1… 5. L’azione effettivamente eseguita viene quindi scelta casualmente da A con probabilità calcolate con la politica π.
Per guidare il cono rigido all’estremità della punta STM in modo che le singole molecole possano essere disposte in un modo specificato, invece di spostarsi semplicemente avanti e indietro, è necessaria una ricetta speciale, e poiché la meccanica su scala nanometrica è così complicata, non è qualcosa di un lo scienziato può facilmente capire o calcolare.
“Ad oggi, tale movimento mirato di molecole è stato possibile solo a mano, attraverso tentativi ed errori”, ha spiegato il Prof. Dr. Stefan Tautz, capo del Quantum Nanoscience Institute di Jülich. “Ma con l’aiuto di un sistema di controllo software autonomo e autoapprendimento, ora siamo riusciti per la prima volta a trovare una soluzione per questa diversità e variabilità su scala nanometrica e ad automatizzare questo processo”.
Allora, cosa lo rende possibile? Un’area dell’apprendimento automatico, chiamato apprendimento per rinforzo (RL), che si occupa del modo in cui gli agenti software dovrebbero agire in un ambiente specifico per aumentare la possibilità di ricevere una ricompensa cumulativa. In questo caso, i ricercatori hanno utilizzato la robotica e l’RL per automatizzare un’attività di manipolazione – lo spostamento di molecole – su scala nanometrica. Quindi, l’algoritmo utilizzato dai ricercatori continuerà a lavorare per risolvere il compito assegnato e ogni volta imparerà dalla sua esperienza.
Il Prof. Dr. Klaus-Robert Müller, capo del dipartimento Machine Learning presso TU Berlin, ha spiegato: “Non prescriviamo un percorso di soluzione per l’agente software, ma piuttosto premiamo il successo e penalizziamo il fallimento”.
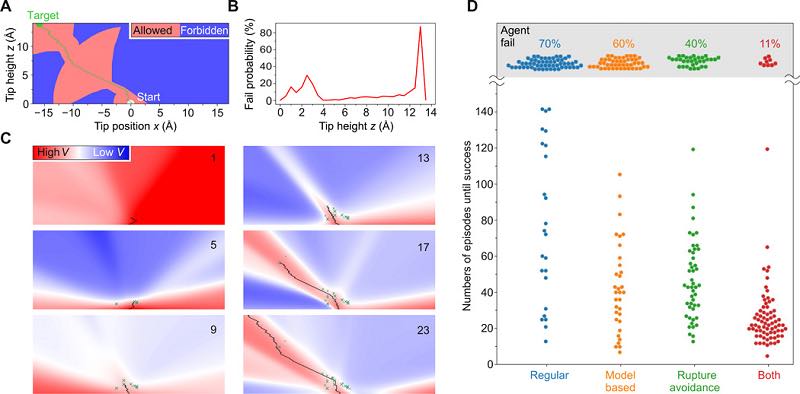
Figura 2. Formazione e prestazioni degli agenti RL. (A) Mappa [sezione 2D attraverso il sistema 3D] dei criteri di rottura del legame sintetico utilizzati per studiare il comportamento dell’agente RL in condizioni controllate. I criteri si basano su una traiettoria sperimentale di successo attorno alla quale è stato creato un corridoio di diametro variabile (rosso chiaro) oltre il quale si rompe il legame (blu). Il diametro del corridoio viene scelto per riprodurre approssimativamente le probabilità sperimentali di rottura del legame (Fig. 1C). Una traiettoria riuscita [vedere (C)] è indicata in verde. (B) Probabilità di guasto dell’agente in intervalli z di 0,5 Å nella simulazione in (A). (C) Progresso di apprendimento di un agente RL. Sei grafici mostrano tagli 2D (y = 0) attraverso la funzione valore codificata a colori V dopo il numero di episodi indicato nell’angolo in alto a destra. Una proiezione 2D della traiettoria dell’agente in ogni episodio viene mostrata come una linea nera. Le croci indicano eventi di rottura del legame innescati secondo i criteri in (A). (D) Diagramma dello sciame che confronta le prestazioni di diversi agenti RL che agiscono nella simulazione (A). Tracciato è il numero di episodi n necessari per eseguire l’attività di rimozione per quattro serie di 80 esperimenti simulati ciascuna. Un esperimento è stato considerato un fallimento dopo 150 episodi falliti. Le rispettive probabilità di guasto dell’agente sono indicate nella parte superiore del grafico. Tracciato è il numero di episodi n necessari per completare l’attività di rimozione per quattro serie di 80 esperimenti simulati ciascuna. Un esperimento è stato considerato un fallimento dopo 150 episodi falliti. Le rispettive probabilità di guasto dell’agente sono indicate nella parte superiore del grafico. Tracciato è il numero di episodi n necessari per completare l’attività di rimozione per quattro serie di 80 esperimenti simulati ciascuna. Un esperimento è stato considerato un fallimento dopo 150 episodi falliti. Le rispettive probabilità di guasto dell’agente sono indicate nella parte superiore del grafico.
Potresti avere familiarità con il sistema AI AlphaGo Zero, una versione del software AlphaGo di DeepMind. Nel 2017, AlphaGo Zero è stato in grado di escogitare autonomamente strategie per vincere una partita complicata, senza dover guardare gli umani giocarci; il sistema è stato in grado di battere i giocatori professionisti in pochi giorni. Ma questo team ha dimostrato il suo approccio RL rimuovendo autonomamente le molecole da una struttura supramolecolare (composta da molte molecole) con un microscopio a sonda di scansione.
“Nel nostro caso, all’agente è stato affidato il compito di rimuovere singole molecole da uno strato in cui sono trattenute da una complessa rete di legami chimici”, ha spiegato il dottor Wagner. “Per essere precisi, si trattava di molecole di perilene, come quelle utilizzate nei coloranti e nei diodi organici a emissione di luce”.
Una delle difficoltà incontrate dai ricercatori è stata che la forza necessaria per muovere le molecole non può superare “la forza del legame con cui la punta dell’STM attrae la molecola” perché si spezzerebbe. Quindi, all’inizio, l’agente software si muoveva in modo casuale e rompeva il legame tra la molecola e la punta del microscopio, ma alla fine ha creato il proprio insieme di regole per garantire che ciò non continuasse.
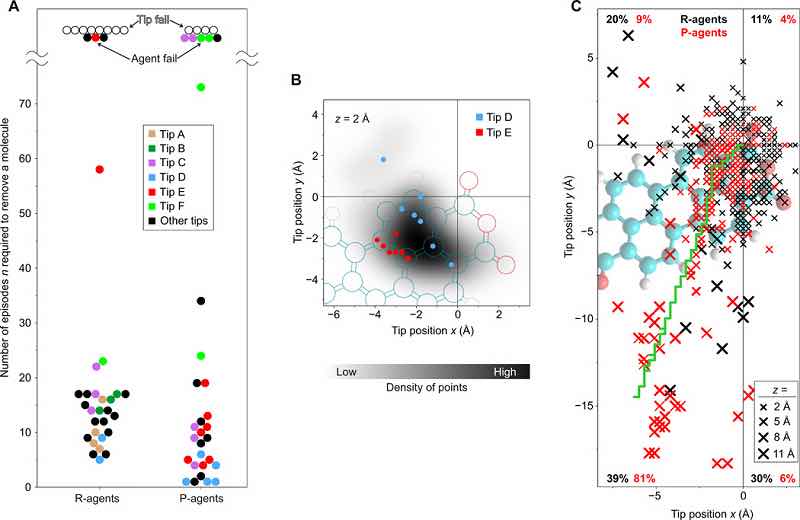
Fig. 3 Prestazioni dell’agente RL nell’esperimento. (A) Diagramma dello sciame del numero di episodi n necessari per completare la rimozione. I gruppi di almeno tre punti dati acquisiti con la stessa punta sono colorati in modo identico (tranne il nero). Se un suggerimento in grado di essere rimosso (dimostrato da un esperimento riuscito) non è riuscito in un altro esperimento, il rispettivo punto dati viene etichettato come “errore dell’agente”. I punti etichettati come “punta non riuscita” indicano suggerimenti con i quali l’attività di rimozione non è mai stata eseguita, sebbene ciò potrebbe, in linea di principio, anche essere un errore dell’agente. (B) Densità delle posizioni (x, y) in cui tutte le traiettorie delle punte (alla fine riuscite) passano attraverso la regione z della più alta probabilità di rottura del legame (z = 2 Å; Fig. 1C). Le posizioni per Tip D (forte) e Tip E (debole) sono indicate da punti. (C) (x, y) proiezioni di tutte le rotture di legame che si verificano entro i primi 10 episodi per gli agenti R e P. Le dimensioni della croce indicano le altezze di rottura z. I numeri citati danno la percentuale di punti di rottura situati in ciascuno dei quattro quadranti del sistema di coordinate. La curva verde mostra l’ultima traiettoria scelta dal P-agent durante la sua preparazione. La sua direzione indica perché gli agenti P hanno una chiara preferenza per esplorare il promettente quadrante inferiore sinistro (B), il che spiega il loro margine di prestazione (A).
Un altro problema che si è verificato a causa dell’uso di RL su scala nanometrica è che gli atomi di metallo che creano la punta dell’STM possono spostarsi leggermente, il che cambia la forza del legame. Ma i ricercatori hanno capito anche questo, facendo apprendere al software “un semplice modello dell’ambiente” in cui la manipolazione avviene parallelamente ai primi cicli. Quindi, l’agente è in grado di allenarsi nella realtà e allo stesso tempo all’interno del proprio modello, il che può davvero accelerare il suo processo di apprendimento.
“Ogni nuovo tentativo aumenta il rischio di un cambiamento e quindi la rottura del legame tra punta e molecola. L’agente software è quindi costretto ad apprendere in modo particolarmente rapido, poiché le sue esperienze possono diventare obsolete in qualsiasi momento. È un po ‘come se la rete stradale, le leggi sul traffico, la carrozzeria e le regole per la guida del veicolo cambiassero continuamente durante la guida autonoma “, ha affermato il Prof. Dr. Stefan Tautz.
“Fino ad ora, questa è stata solo una ‘prova di principio’. Tuttavia, siamo fiduciosi che il nostro lavoro aprirà la strada alla costruzione automatizzata assistita da robot di strutture supramolecolari funzionali, come transistor molecolari, celle di memoria o qubit, con una velocità, precisione e affidabilità di gran lunga superiori a quelle attualmente disponibili. possibile.”