NVIDIA Neuralangelo Research ri-costruisce le scene 3D
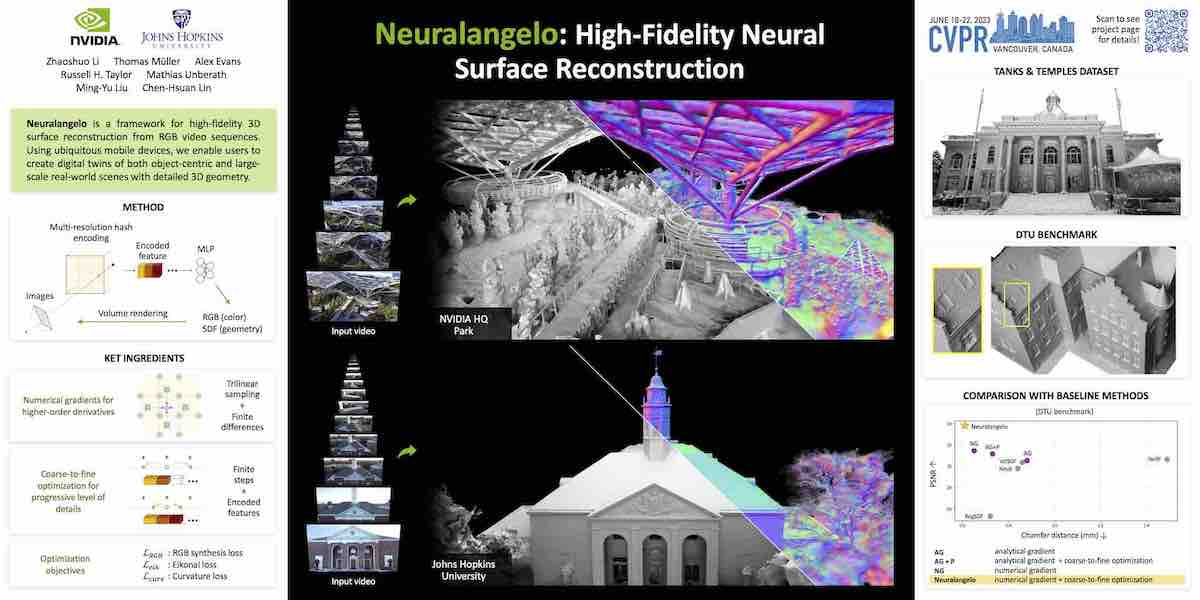
Neuralangelo, il nuovo modello AI di NVIDIA Research per la ricostruzione 3D utilizzando reti neurali, è in grado di trasformare clip video 2D in dettagliate strutture 3D, creando realistiche repliche virtuali di edifici, sculture e altri oggetti del mondo reale.
Come Michelangelo che scolpiva incredibili visioni realistiche da blocchi di marmo, Neuralangelo genera strutture 3D con intricati dettagli e texture. I professionisti creativi possono quindi importare questi oggetti 3D in applicazioni di progettazione, modificarli ulteriormente per l’utilizzo nell’arte, nello sviluppo di videogiochi, nella robotica e nei gemelli digitali industriali.
La capacità di Neuralangelo di tradurre le trame di materiali complessi, come tegole, lastre di vetro e marmo liscio, dai video 2D alle risorse 3D supera di gran lunga i metodi precedenti. La sua elevata fedeltà rende le ricostruzioni 3D più facili per sviluppatori e professionisti creativi, consentendo loro di creare rapidamente oggetti virtuali utilizzabili nei loro progetti, utilizzando filmati acquisiti da smartphone.
“Le capacità di ricostruzione 3D offerte da Neuralangelo saranno un enorme vantaggio per i creatori, aiutandoli a ricreare il mondo reale nel mondo digitale”, ha affermato Ming-Yu Liu, direttore senior della ricerca e co-autore dello studio. “Questo strumento consentirà agli sviluppatori di importare oggetti dettagliati, sia essi piccole statue o enormi edifici, in ambienti virtuali per videogiochi o gemelli digitali industriali”.
In una dimostrazione, i ricercatori di NVIDIA hanno mostrato come il modello potrebbe ricostruire oggetti iconici come il David di Michelangelo e oggetti comuni come un camion a pianale. Neuralangelo è in grado anche di ricostruire gli interni e gli esterni degli edifici, come dimostrato da un dettagliato modello 3D del parco situato presso il campus della Bay Area di NVIDIA.
Il modello di rendering neurale vede in 3D
I modelli precedenti di intelligenza artificiale per la ricostruzione delle scene 3D hanno faticato nel catturare con precisione modelli di texture ripetitivi, colori omogenei e forti variazioni cromatiche. Neuralangelo utilizza le primitive grafiche neurali istantanee, la tecnologia alla base di NVIDIA Instant NeRF, per aiutare a catturare questi dettagli più fini.
Utilizzando un video 2D di un oggetto o di una scena ripreso da varie angolazioni, il modello seleziona diversi fotogrammi che catturano punti di vista differenti, proprio come un artista che considera un soggetto da varie angolazioni per ottenere una sensazione di profondità, dimensione e forma.
Una volta determinata la posizione della telecamera per ogni fotogramma, l’intelligenza artificiale di Neuralangelo crea una rappresentazione approssimativa della scena in 3D, come uno scultore che inizia a dare forma al soggetto.
Il modello ottimizza quindi il rendering per rendere i dettagli più nitidi, proprio come uno scultore che intaglia con precisione la pietra per riprodurre la trama di un tessuto o una figura umana.
Il risultato finale è un oggetto 3D o una scena di grande scala utilizzabile in applicazioni di realtà virtuale, gemelli digitali o sviluppo robotico.
NVIDIA Research sarà presente al CVPR dal 18 al 22 giugno
Neuralangelo è uno dei quasi 30 progetti di NVIDIA Research che saranno presentati alla Conference on Computer Vision and Pattern Recognition (CVPR), che si terrà dal 18 al 22 giugno a Vancouver. I documenti copriranno argomenti come la stima della posa, la ricostruzione 3D e la generazione di video.
Uno di questi progetti, DiffCollage, è un metodo di diffusione che crea contenuti su larga scala, inclusi panorami orizzontali lunghi, panorami a 360 gradi e immagini in movimento in loop. Quando viene alimentato un set di dati di addestramento di immagini con proporzioni standard, DiffCollage tratta queste immagini più piccole come sezioni di un oggetto visivo più grande, come pezzi di un collage. Ciò consente ai modelli di diffusione di generare contenuti di grandi dimensioni con un aspetto coerente, senza essere addestrati su immagini della stessa scala.
La tecnica può anche trasformare le richieste di testo in sequenze video, come dimostrato utilizzando un modello di diffusione preaddestrato che cattura il movimento umano.
title={Neuralangelo: High-Fidelity Neural Surface Reconstruction},
author={Li, Zhaoshuo e M\”uller, Thomas e Evans, Alex e Taylor, Russell H e Unberath, Mathias e Liu, Ming-Yu e Lin, Chen-Hsuan},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition ({CVPR})},
year={2023}
}